
[Python]Cloud DataflowからCloud SQLに接続する
はじめに
こんにちは。開発チームの南です。 GCPのETLサービスであるCloud Dataflowですが、 BigQueryやDatastoreとの連携は、SDKとして用意されていますがCloud SQLはありません。 ということで今回はCloud DataflowからCloud SQLに接続する方法について紹介します。
対象読者
Cloud Dataflowを利用したことがある。 Cloud DataflowからCloud SQLを利用したい。
手順
以下の手順で実装していきます。
- Cloud SQLのプライベートIPを有効する
- Cloud DataflowのParDoにてCloud SQLに接続する
- Cloud Dataflow起動時にCloud SQLに接続しているネットワークを指定する
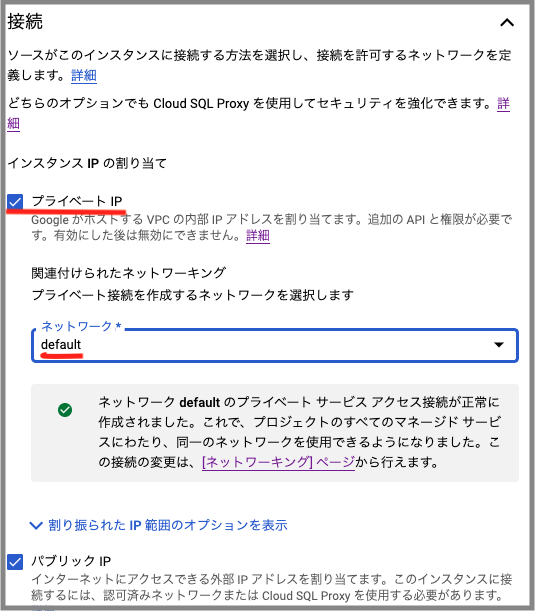
1. Cloud SQLのプライベートIPを有効する
Cloud SQLインスタンスにプライベートIPを使用して接続します。 また、プライベート接続を作成するネットワークを選択する必要があります。 今回は「default」というネットワークを選択しました。
テスト用のテーブルを以下のように作成しました。
CREATE DATABASE connect_by_dataflow DEFAULT CHARACTER SET utf8;
USE connect_by_dataflow;
SET SQL_SAFE_UPDATES=0;
CREATE TABLE `users` (
`id` CHAR(8) not null primary key,
`name` VARCHAR(100) not null
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
2. Cloud DataflowのParDoにてCloud SQLに接続する
ここからは、Cloud DataflowからCloud SQLに接続するコードを書いていきます。 まずは、apache beamの公式が提供しているパッケージとmysqlに接続するためパッケージをインストールします。
pip install 'apache-beam[gcp] mysql-connector-python
次にCloud Dataflowを起動するためのソースコードを書きます。 インメモリからデータを読み込み、先ほと作成したCloud SQLのusersテーブルに挿入するコードになっています。
import apache_beam as beam
from apache_beam.options.pipeline_options import PipelineOptions
import mysql.connector as mydb
import argparse
import logging
class WriteToCloudSQL(beam.DoFn):
def __init__(self, host, password):
self.host = host
self.password = password
def process(self, message):
id = message["id"]
name = message["name"]
try:
conn= mydb.connect(
host=self.host,
user="root",
password=self.password,
database="connect_by_dataflow"
)
cursor = conn.cursor()
insert = "INSERT INTO users VALUES(%s,%s)"
cursor.execute(insert, (id, name))
except Exception as e:
print(e)
conn.commit()
conn.close()
def run(
host,
password,
pipeline_args=None
):
pipeline_options=PipelineOptions(
pipeline_args,
streaming=False,
save_main_session=True
)
with beam.Pipeline(options=pipeline_options) as p:
(p
| beam.Create([
{"id": "20220001", "name": "curucuru太郎"}
])
| beam.ParDo(WriteToCloudSQL(host, password))
)
if __name__=='__main__':
logging.getLogger().setLevel(logging.INFO)
parser = argparse.ArgumentParser()
parser.add_argument(
"--cloudsql_host"
)
parser.add_argument(
"--cloudsql_password"
)
known_args, pipeline_args = parser.parse_known_args()
run(
known_args.cloudsql_host,
known_args.cloudsql_password,
pipeline_args
)
3. Cloud Dataflow起動時にCloud SQLに接続しているネットワークを指定する
最後に、作成したCloud Dataflowを起動します。 起動時に、Cloud SQLに接続しているネットワークを指定する必要があります。 また、mysql接続時に指定するhostは、Cloud SQLのプライベートIPにします。
python connect_cloudsql.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--temp_location=${TEMP_LOCATION} \
--runner=DataflowRunner \
--requirements_file=./requirements.txt \
--machine_type=n1-standard-1 \
--network=${CLOUDSQL_NETWORK} \
--cloudsql_host=${CLOUDSQL_PRIVATE_IP} \
--cloudsql_password=${CLOUDSQL_PASSWORD}
最後に
今回は、Cloud DataflowからCloud SQLに接続する方法を紹介しました。 今回、紹介した方法が皆さんの参考になれば幸いです。
CURUCURUでは、仲間になってくれるエンジニアの方を募集しております! 少しでも興味をお持ちいただけたら、気軽にカジュアル面談しませんか? ご応募お待ちしております! https://www.wantedly.com/companies/curucuru
